Análisis de Datos de Kickstarter¶
Diego Ortego P., Simon Grass, Victor Faraggi V. Primavera 2018
import IPython as ip
print("IPython Imported")
import random
print("Random Imported")
import pandas as pd
print("Pandas Imported")
from pandas.api.types import CategoricalDtype
print("Pandas type Imported")
import numpy as np
print("Numpy Imported")
import matplotlib
import matplotlib.pyplot as plt
%matplotlib inline
matplotlib.style.use('ggplot')
print("Matplotlib Imported")
from ggplot import *
print("GGPlot Imported")
from tqdm import tqdm_notebook as tqdm
print("TqDm Imported")
import seaborn as sns
print("SeaBorn Imported")
from sklearn import preprocessing
print("PreProcessing Imported")
from sklearn.utils import check_X_y
print("PreProcessing Aid Imported")
from sklearn.dummy import DummyClassifier
print("DummyClassifier Imported")
from sklearn.svm import SVC
print("SupportVectorMachineClassifier Imported")
from sklearn.tree import DecisionTreeClassifier
print("DecisionTreeClassifier Imported")
from sklearn.naive_bayes import GaussianNB
print("GaussianNaiveBayesClassifier Imported")
from sklearn.neighbors import KNeighborsClassifier
print("KNeighborsClassifier Imported")
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_validate
from sklearn.model_selection import cross_val_predict
print("Train/Test data Splitters Imported")
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
print("Metrics Imported")
from sklearn.metrics import classification_report
print("Metrics Report Imported")
from mlxtend.preprocessing import TransactionEncoder
print("Transaction Encoder Imported")
from efficient_apriori import apriori
print("Apriori Algorithm Imported")
# Data Import
kickstarter_2016 = pd.read_csv("kickstarter_2016_fixed.csv")
kickstarter_2018 = pd.read_csv("kickstarter_2018_fixed.csv")
print("Dataset Imported")
# Column names are standardized
kickstarter_2016 = kickstarter_2016.rename(columns = {'ID ': 'ID', 'name ': 'name', 'category ': 'category', 'main_category ': 'main_category', 'currency ': 'currency', 'goal ': 'goal', 'deadline ': 'deadline', 'launched ': 'launched', 'pledged ': 'pledged', 'state ': 'state', 'backers ': 'backers', 'country ': 'country', 'usd pledged ': 'usd pledged'})
print("Dataset Column Names Standardized")
# Data types are set correctly
for data_frame in [kickstarter_2016, kickstarter_2018]:
data_frame[['category']] = data_frame[['category']].astype('category')
data_frame[['main_category']] = data_frame[['main_category']].astype('category')
data_frame[['currency']] = data_frame[['currency']].astype('category')
data_frame[['goal']] = data_frame[['goal']].astype('int64')
data_frame[['deadline']] = data_frame[['deadline']].astype('datetime64[ns]')
data_frame[['launched']] = data_frame[['launched']].astype('datetime64[ns]')
data_frame[['pledged']] = data_frame[['pledged']].astype('int64')
data_frame[['state']] = data_frame[['state']].astype('category')
data_frame[['backers']] = data_frame[['backers']].astype('int64')
data_frame[['country']] = data_frame[['country']].astype('category')
data_frame[['usd pledged']] = data_frame[['usd pledged']].astype('int64')
kickstarter_2018[['usd_pledged_real']] = kickstarter_2018[['usd_pledged_real']].astype('int64')
print("Dataset Types Casted")
Introducción¶
Motivación¶
¿Cuál es el contexto general del tema/problema/datos que eligió estudiar?¶
Este proyecto utiliza datos recolectados de diferentes proyectos de Kickstarter. Kickstarter es una plataforma que permite el financiamiento público de proyectos de diferente índole. En esta se encuentran proyectos que van desde arte y música hasta computación y robótica. Lo que hace destacar a Kickstarter es el modelo de financiamiento que permite: El apoyo monetario directo de otras personas. Este “apoyo directo” se traduce de manera simbólica o monetaria, es también conocido como crowdfunding. Así, el éxito de un proyecto depende de la opinión que el público tiene de él.
En resumen, Kickstarter permite la innovación y el desarrollo que el mundo quiera ver.
¿Por que podría ser de interés estos datos?¶
La “Innovación” y el “Emprendimiento” son aspectos importantísimos para la ingeniería y la vida laboral en general, por esto saber si tu proyecto está enfocado correctamente hacia las expectativas del público puede ser la diferencia entre el fracaso máximo, o el éxito rotundo.
La consultoría es una parte integral del negocio de la Innovación, que empresas grandes se benefician mucho consiguiendo, sin embargo conseguir ayuda de este tipo puede estar lejos de lo pagable por una empresa pequeña, como las que recurren a KickStarter para financiar sus proyectos. Por esto la confección de una guía pública de recomendaciones y pasos a seguir para tener éxito en crowdfunding es un proyecto especialmente útil para la comunidad.
Nos preguntamos por que proyectos como MIGO y Buccaneer no fueron ambos exitosos siendo que como idea eran extremadamente parecidas. La idea de analizar estos datos es poder encontrar patrones en las características de los proyectos que contribuyan a que estos sean exitosos. Las metas y fechas que utilizan, la cantidad de dinero que piden, y otras características que puedan ser capaces de beneficiar o perjudicar el proyecto. Con los datos de Kickstarter del año 2016 y 2018 esperamos poder predecir si un proyecto va a ser o no exitoso.
Descubrimientos en esta área no solo se podrían ver reflejados en futuros proyectos Kickstarter, sino en cualquier proyecto crowdfunding que se haga en cualquier plataforma. Podemos notar que tanto la vida personal como familiar, académica, laboral, etc.. está llena de proyectos (con metas, planes de acción, éxitos y fracasos) por lo que entender el cómo distintas tomas de iniciales puede afectar en el resultado de estos es clave.
A partir de esto entonces buscamos entender, ¿qué es lo que hace que un proyecto sea cancelado, por ejemplo, será simplemente que se pidió mucho presupuesto y se vio que no se iba a alcanzar la meta? ¿O tiene esto más que ver con las fechas que se utilizaron para conseguir las distintas metas, o con que el plan de acción no generaba suficiente tracción? Incluso tal vez simplemente con el país en que se ejecutó; países menos enfocados en la tecnología tienen probablemente menos oportunidades de encontrar gente dispuesta a invertir en proyectos tecnológicos que puedan generar valor a futuro. Toda esta información puede ser traspasada y generalizada. Dado que si se logra sacar más proyectos adelante, la sociedad como conjunto avanza en aspectos de tecnología, salud, e incluso simplemente calidad de vida.
Temática¶
Cada día se generan una gran cantidad de ideas potencialmente muy beneficiosas para la sociedad, la gran mayoría de estas no sale adelante, y el problema nace no de lo buena o útil que sea la idea, simplemente ocurre porque la idea no se vende de la manera correcta. A partir de esto, nos gustaría ver que características ayudan a que un proyecto sea exitoso, y de esta forma poder generar una especie de "Guía" para poder maximizar las posibilidades de éxito de los proyectos.
Formular estos de tal forma que sean más atractivos para el usuario, pero no analizando el comportamiento del humano sino simplemente viendo los patrones de una enorme cantidad de datos. Estos datos a priori pueden no parecer tener ninguna relación con el resultado del proyecto, pero la belleza de la minería de datos nace en encontrar estas recurrencias donde parece no haberlas a simple vista.
Es por eso que nos gustaría analizar estos datos como "Categorías del proyecto" , "Cantidad de dinero solicitada", "País de realización", etc. y sacar conclusiones válidasal respecto (para esto los datos tienen la columna "estado" que nos dice si el proyecto fue exitoso o no).
Para poder lograr este proceso hay que partir con una limpieza de datos, con el fin de alinear las características de estos y poder analizarlos correctamente, la limpieza de datos nos permite minimizar el ruido y filtrar las características relevantes para lo que queremos lograr. Luego se ordenan y grafican los datos de distintas formas con el fin de observarlos mejor. Después, ya de manera no tan preliminar, sigue el entrenar un algoritmo pertinente que sea capaz de predecir el éxito de proyectos con un porcentaje suficientemente alto (mejor que la aleatoriedad, y que otras bases de referencia).
Hipótesis preliminar¶
A partir del dataset se busca identificar diferentes factores que infouyan en el éxito de los proyectos en Kickstarter.
Así, se tiene las siguientes hipótesis:
Para empezar, que existe un método predictivo aplicable al dataset que permita generar resultados confiables, superior a la categorización al azar.
Los proyectos que se financian por más tiempo tienden a tener éxito.
Los proyectos tecnólogicos son más financiados.
Mientras más fondos se necesiten, más se financia.
Los proyectos que están en dólares tienen tienden a tener éxito.
Los proyector norteamericanos tienden a tener mas éxito.
Los proyectos cuyos resultados no necesitan ser distribuidos físicamente tinden a ser más financiados.
Entre proyectos concurrentes (en financiación al mismo tiempo) y que tienen que ver con lo mismo los recursos de financiamiento se dividen entre ellos por culpa de la competencia.
Descripción de los Datos que se van a Utilizar¶
Descripción preliminar¶
El dataset a ocupar corresponde a una compilacion de datos extraidos de la Kickstarter Platform durante los anios 2016 y 2018, reunidos a tablas en formato .csv para Kaggle de libre acceso aqui, por Mickaël Mouillé bajo la licencia CC BY-NC-SA 4.0.
print(kickstarter_2016.shape)
print(kickstarter_2018.shape)
Se observa una fila para entender como esta presentado el dataframe kickstarter16.
print(kickstarter_2016.iloc[1])
Y una fila para entender como esta presentado el dataframe kickstarter18 también.
print(kickstarter_2018.iloc[1])
Las dimensiones de las tablas de datos son relativamente grandes, como se ve arriba, y no comparten la misma cantidad de columnas de atributos.
Sus pesos en formato csv son 42.9 MB para el 2016 y 52.2 MB para el 2018.
Características relevantes¶
Análisis de los atributos para el dataset del 2016¶
Se realiza un resumen estadistico del dataframe en el cual trabajaremos.
kickstarter_2016.describe(include='all')
Luego, se identifica el tipo de datos que hay en cada columna de este.
print(kickstarter_2016.dtypes)
ID:¶
Una columna de indices numericos, sus datos estadisticos son de poca reelevancia, pero son llave primaria de la tabla, es decir, cada fila tiene un indice unico.
row_amount16 = len(kickstarter_2016['ID'])
print(row_amount16)
print(len(kickstarter_2016['ID'].unique()))
name:¶
Tiene un string con el nombre de cada proyecto, donde algunos nombres (2134 de ellos) se repiten y existe un valor invalido.
print(row_amount16 - len(kickstarter_2016['name'].unique()))
category:¶
Contiene un string con el nombre de una de 771 categorias especificas a las que pertenecen los proyectos.
print(len(kickstarter_2016['category'].unique()))
main_category:¶
Contiene un string con el nombre se una de 120 categorias mas amplias a las que pertenecen los proyectos.
print(len(kickstarter_2016['main_category'].unique()))
currency:¶
Contiene un string con la sigla de una de las monedas del mundo (o un tipo de item que en particular que necesiten), que indica en que moneda se aceptaron fondos para el proyecto.
print(len(kickstarter_2016['currency'].unique()))
deadline:¶
Contiene una fecha y hora en la que se habria fijado la meta de recaudacion del proyecto. Las fechas y horas raramente se repiten entre proyectos distintos. Así, al remover los duplicados, se puede observar que 28937 de 323750 proyectos tienen fechas de meta idénticas.
print(len(kickstarter_2016['deadline'].unique()))
print(row_amount16 - len(kickstarter_2016['deadline'].unique()))
kickstarter_2016['launched'].describe()
pledged:¶
Contiene un número que indica la cantidad de dinero aportado directamente por las personas. Cabe destacar que esta cantidad se encuentra en la moneda original con la que se inició el proyecto. Es decir, esto no está necesariamente dolares.
kickstarter_2016['pledged'].describe()
state:¶
Contiene un string que indica el estado que se encuentra el proyecto. Para nuestro estudio los valores que más nos interesarán son "failed" o "successful".
kickstarter_2016['state'].value_counts()
backers:¶
Contiene la cantidad de personas que han apoyado a cada proyecto. Este apoyo no necesariamente es monetario ya que existe una columna específica para esto.
kickstarter_2016['backers'].describe()
country:¶
Contiene el ID de país de origen de los diferentes proyectos. Este ID corresponde a la codificación internacional de paises ISO 2.
kickstarter_2016['country'].value_counts()
Podemos identificar de inmediato que Estados Unidos es el país que alberga la mayor cantidad de proyectos, seguido del Reino Unido.
Se puede ademas observar el ingreso correcto de los paises de origen de los proyectos de acuerdo al código ISO2, con la unica excepcion del codigo N.
Al verificar esto con la lista oficial de códigos de países se puede notar que "HK" corresponde a Hong Kong. Aunque este no sea un país si tiene su propio código ISO. Con respecto al valor "N", una exploración del archivo .csv permite identicar que este siempre está acompañado por el state undefined, backers igual a cero y usd.pledged igual a cero. De esto se podría deducir que la información de estos datos no fue compartida para la elaboración del dataset.
usd.pledged:¶
Esta columna contiene la cantidadd de dinero aportado a cada proyecto en dolares americanos.
kickstarter_2016['usd pledged'].describe()
Esta columna se podría usar, por ejemplo, para medir la diferencia una conversión de 1 GBP (libras británicas) a USD. Destacamos que 1 GBP corresponde a alrededor de 1.35 USD.
Análisis de los atributos para el dataset del 2018¶
kickstarter_2016.describe(include='all')
usd_pledged_real, usd_goal_real :¶
Sabemos que las columnas usd.pledged y usd.goal equivalen a goal y pledged, que pueden estar en cualquier moneda, convertidos a dólares estadounidenses. Sin embargo, no tenemos información de como fue realizado este cambio.
Estas dos columnas introducidas en el dataset del 2018 buscan aportar la misma información pero sabemos como se realizó el cambio. Este fue realizado mediante la api fixer.io. Esta provee conversión de monedas de acuerdo a los precios actuales e históricos de estas. Esta api utiliza los datos de bancos y diferentes entidades financieras. Por lo tanto, se podría afirmar que este cambio es confiable y real.
Preprocesamiento de los datasets¶
A partir de los primeros estudios de los atributos de los datasets se identificaron errores en el ingreso del atributo name que producian desplazamiento de los atributos de ciertas filas. Así, se obtenían columnas adicionales o columnas faltantes para algunas filas. Esto se debía a la incompatibilidad del formato de almacenamiento del dataset en csv con los nombres de algunos proyectos. El formato de los archivos usa comas como separadores de atributos y los nombres de estos proyectos conflictivos tenían comas, puntocomas y "/t" en ellos. Dado esto R reconocía como separador algunas partes de estos nombres de proyectos. Las columnas faltantes de algunos datos se debía a la falta de cuatro comas al final de cada ítem del archivo.
Se utilizó el siguiente script de Python para solucionar estos problemas generando un nuevo csv corregido, "kickstarter_2016_fixed.csv" y "kickstarter_2018_fixed.csv":
import csv
def replacement(s, sub, new_sub, nth):
find = s.find(sub)
# if find is not p1 we have found at least one match for the substring
i = find != -1
# loop util we find the nth or we find no match
while find != -1 and i != nth:
# find + 1 means we start at the last match start index + 1
find = s.find(sub, find + 1)
i += 1
# if i is equal to nth we found nth matches so replace
if i == nth:
return s[:find] + new_sub + s[find + len(sub):]
return s
with open("kickstarter_2016.csv", "rb") as infile, open("kickstarter_2016_fixed.csv", "w", newline='') as outfile:
writer = csv.writer(outfile, delimiter=",")
line = str(infile.readline().decode(errors='ignore'))
while line != "":
items = line.rsplit(",")
if line.find("\t") != -1:
line = line.replace('\t', "")
items = line.rsplit(",")
if line.find(";") != -1:
line = line.replace(';', "")
items = line.rsplit(",")
while line.find(",,") != -1:
line = line.replace(",,", ",")
items = line.rsplit(",")
while len(items) > 14:
line = replacement(line, ",", " ", 2)
items = line.rsplit(",")
if len(items) < 14:
items.insert(1, "")
items.pop()
writer.writerow([item.replace('"', '') for item in items])
line = str(infile.readline().decode(errors='ignore'))
with open("kickstarter_2018.csv", "rb") as infile, open("kickstarter_2018_fixed.csv", "w", newline='') as outfile:
writer = csv.writer(outfile, delimiter=",")
line = str(infile.readline().decode(errors='ignore'))
while line != "":
items = line.rsplit(",")
if line.find("\t") != -1:
line = line.replace('\t', "")
items = line.rsplit(",")
if line.find(";") != -1:
line = line.replace(';', "")
items = line.rsplit(",")
while line.find(",,") != -1:
line = line.replace(",,", ",")
items = line.rsplit(",")
while len(items) > 15:
line = replacement(line, ",", " ", 2)
items = line.rsplit(",")
if len(items) < 15:
items.insert(1, "")
items.pop()
writer.writerow([item.replace('"', '') for item in items])
line = str(infile.readline().decode(errors='ignore'))
Pre Visualizacion de los Datos ocupando R¶
Antes de empezar la visualizacion cabe notar que esta fue realizada ocupando el paquete 'ggplot2' de R, y por lo tanto se incluye el codigo que produjo los plots aqui, empezando por la carga de los datos en R:
Codigo en R¶
# if ("kableExtra" %in% rownames(installed.packages()) == FALSE)
# {
# install.packages("kableExtra", dependencies=TRUE)
# }
# library(kableExtra)
# if ("countrycode" %in% rownames(installed.packages()) == FALSE)
# {
# install.packages("countrycode", dependencies=TRUE)
# }
# library(countrycode)
# if ("ggplot2" %in% rownames(installed.packages()) == FALSE)
# {
# install.packages("ggplot2", dependencies=TRUE)
# }
# library(ggplot2)
# if ("plyr" %in% rownames(installed.packages()) == FALSE)
# {
# install.packages("plyr", dependencies=TRUE)
# }
# library(plyr)
# if ("plotrix" %in% rownames(installed.packages()) == FALSE)
# {
# install.packages("plotrix", dependencies=TRUE)
# }
# library(plotrix)
# if ("scales" %in% rownames(installed.packages()) == FALSE)
# {
# install.packages("scales", dependencies=TRUE)
# }
# library(scales)
# kickstarter16 <- read.csv(file = "kickstarter_2016_fixed.csv", fileEncoding="latin1")
# kickstarter18 <- read.csv(file = "kickstarter_2018_fixed.csv", fileEncoding="latin1")
# row_amount16 <- length(kickstarter16[,1])
Estadísticas y Visualización¶
En esta sección se estudian diferentes características de los datos del dataset correspondiente al 2016
Se estudia las proporciones de los resultados de los proyectos. Interesa conocer sobretodo las proporciones de los proyectos "successful" y "failed".
Codigo en R¶
# df <- as.data.frame(table(kickstarter16$state))
# colnames(df)[1] <- "Estado"
# colnames(df)[2] <- "CantidadProyectos"
# bp<- ggplot(df, aes(x="", y=CantidadProyectos, fill=Estado))+
# geom_bar(width = 1, stat = "identity")
# pie <- bp + coord_polar("y", start=0)+ theme(axis.text.x=element_blank())
# pie
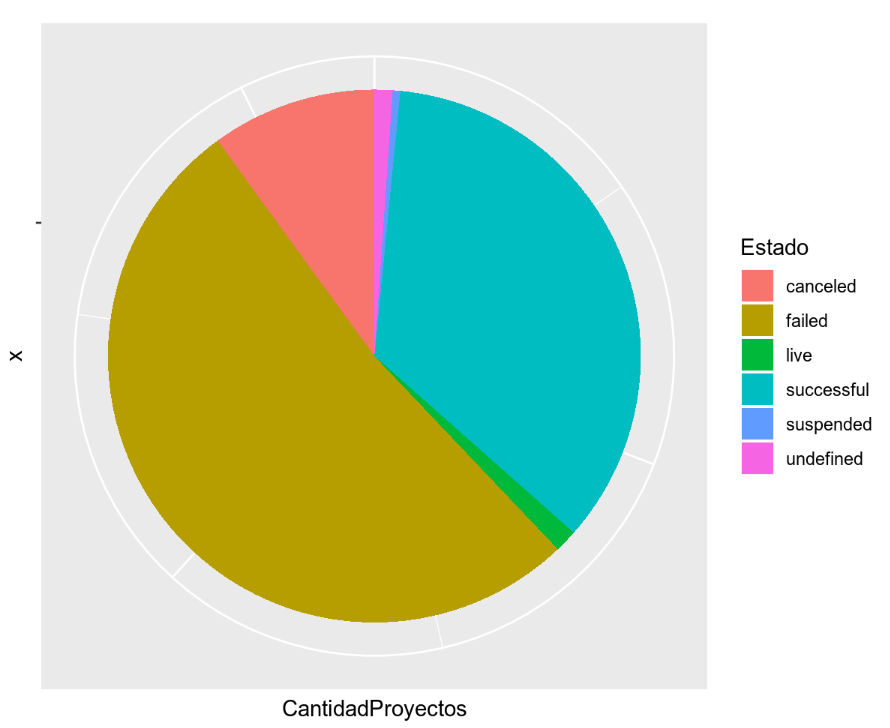
Podemos observar que más del 50% de los proyectos han fallado en alcanzar su meta de financiamiento. Asimismo alrededor de un 35% de los proyecto la han logrado. Las proporciones de "canceled" y "suspended" son significativas y muestran que un gran número de proyectos se desploman antes de siquiera llegar a la fecha de meta.
A continuación, se estudian los porcentajes de proyectos exitosos dentro de cada categoría. Por ejemplo, se busca conocer el porcentaje de proyectos de la categoría de "Technology" que es exitoso.
Codigo en R¶
# a <- count(kickstarter16$main_category)
# b <- count(kickstarter16[kickstarter16$state == "successful",]$main_category)
# ar <- c(100*(b$freq/a$freq))
# c <- data.frame(x=a$x, y=ar)
# ggplot(c,
# aes(x = c$x,
# y = c$y)) +
# geom_bar(stat="identity") +
# coord_flip() + xlab("Categorias") + ylab("Porcentaje de proyectos exitosos") + theme(text = element_text(size = 18), axis.title.x = element_text( hjust = 1))
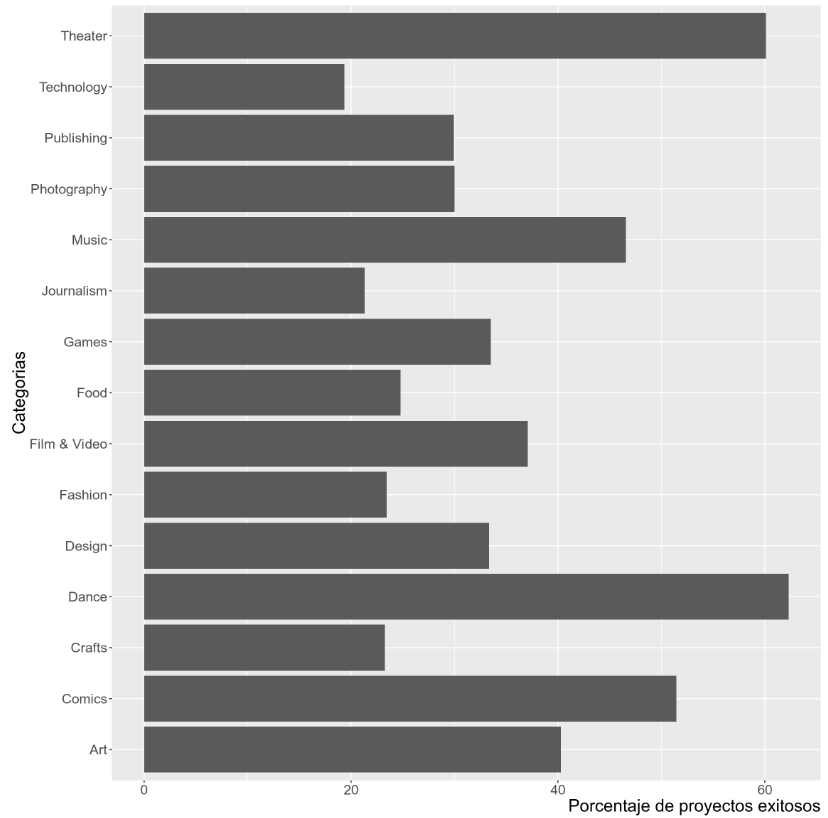
A partir del gráfico, se puede observar que las categorías que más exito tienen son "Theater", "Dance" y "Comics". Sorprendentemente se observa que más de un 60% de los proyectos de Danza resultan exitosos. De la misma manera, menos de un 20% de los proyectos ligados al área tecnologica resulta exitoso. Esto último viene a refutar una de las hipótesis preliminares en la cual se afirmaba lo contrario.
Ahora, se estudia el porcentaje de proyectos exitosos con respecto al país donde se lanzaron. Cabe decir, que se espera que Estados Unidos y Gran Bretaña lideren estos porcentajes dada la gran cantidad de proyectos provenientes de estos países.
Codigo en R¶
# a <- count(kickstarter16$country)
# b <- count(kickstarter16[kickstarter16$state == "successful",]$country)
# ar <- c(100*(b$freq/a$freq))
# c <- data.frame(x=a$x, y=ar)
# ggplot(c,
# aes(x = c$x,
# y = c$y)) +
# geom_bar(stat="identity") +
# coord_flip() + xlab("Paises") + ylab("Porcentaje proyectos exitosos") + theme(text = element_text(size = 18), axis.title.x = element_text( hjust = 1))
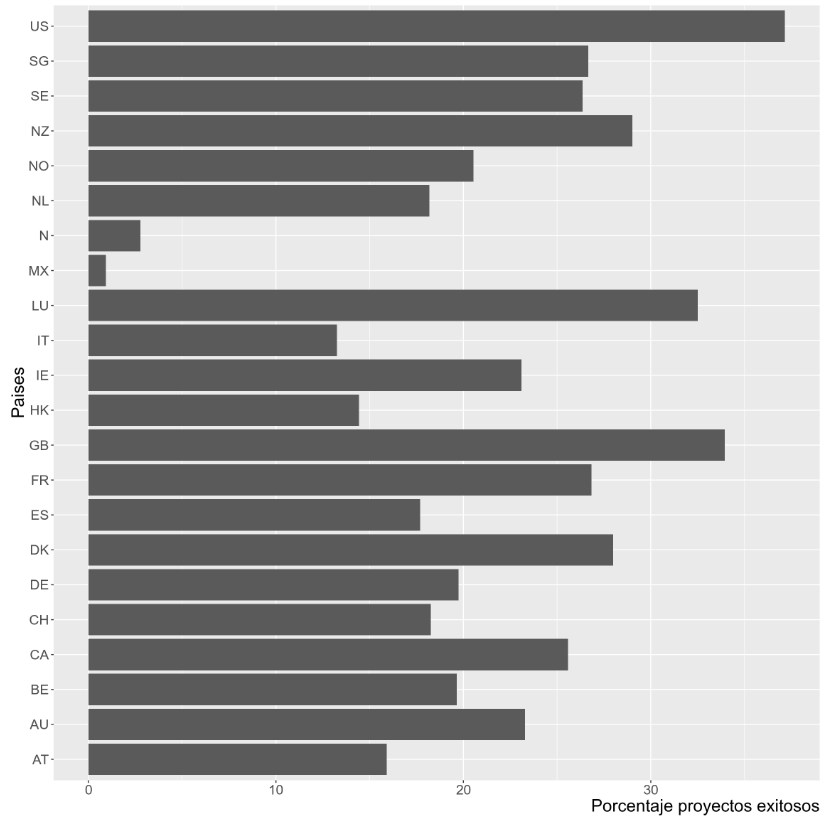
El gráfico anterior reafirma la hipótesis que se tenía con respecto a Estados Unidos y Gran Bretaña. De la misma manera, arroja un resultado particularmente interesante: Luxemburgo, con solo 40 proyectos, es el tercer país con el mayor porcentaje de proyectos exitosos.
Siguiendo la línea del estudio por país, se explora los porcentajes de éxito por moneda. Al igual que en el estudio anterior, se espera que la lista la lideren los USD y los GBP.
Codigo en R¶
# a <- count(kickstarter16$currency)
# b <- count(kickstarter16[kickstarter16$state == "successful",]$currency)
# ar <- c(100*(b$freq/a$freq))
# c <- data.frame(x=a$x, y=ar)
# ggplot(c,
# aes(x = c$x,
# y = c$y)) +
# geom_bar(stat="identity") +
# coord_flip() + xlab("Monedas") + ylab("Porcentaje de proyectos exitosos") + theme(text = element_text(size = 18), axis.title.x = element_text( hjust = 1))
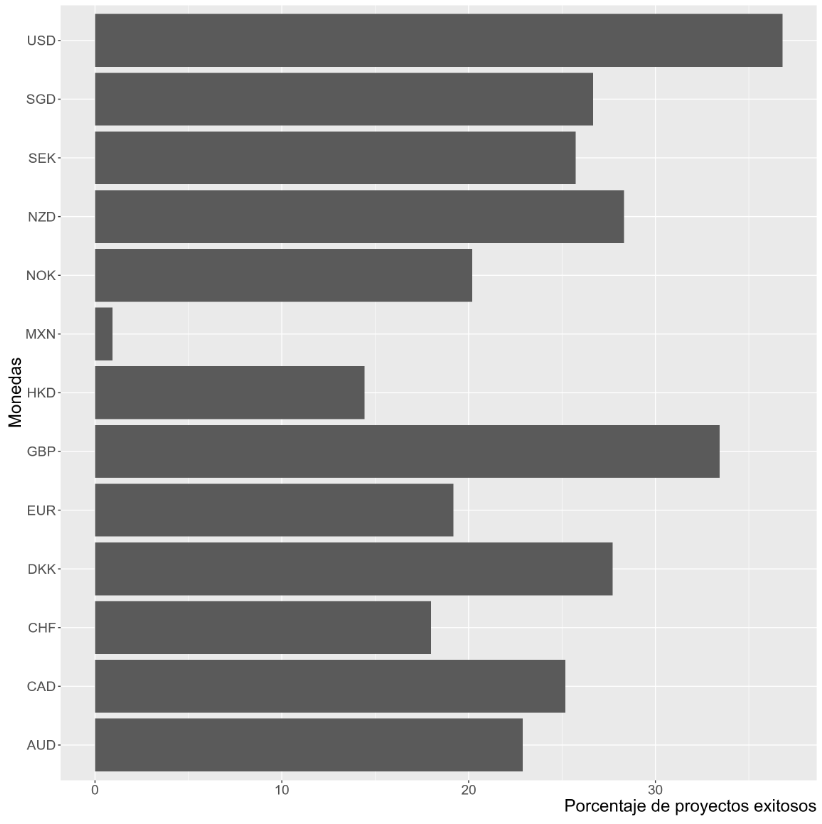
De acuerdo a nuestras hipótesis, los dolares estadounidenses y las libras esterlinas lideran con los mayores porcentajes de éxito. Del resto de las monedas, ninguna destaca e incluso se observa que los euros tienen uno de los porcentajes de éxito más bajos.
Finalmente, se busca estudiar si la duración de un proyecto (deadline - launchdate) puede resultar una elección importante a la hora de buscar el éxito de este.
Codigo en R¶
# ar <- c(as.Date(kickstarter16$deadline)-as.Date(kickstarter16$launched))
# c <- data.frame(x=kickstarter16$state, y=ar)
# ggplot(c,
# aes(x = c$x,
# y = c$y,
# fill = c$x)) +
# geom_boxplot() +
# coord_flip(ylim = c(0, 100)) + xlab("Estado del Proyecto") + ylab("Duración en dias") + theme(text = element_text(size = 13), axis.title.x = element_text( hjust = 1))
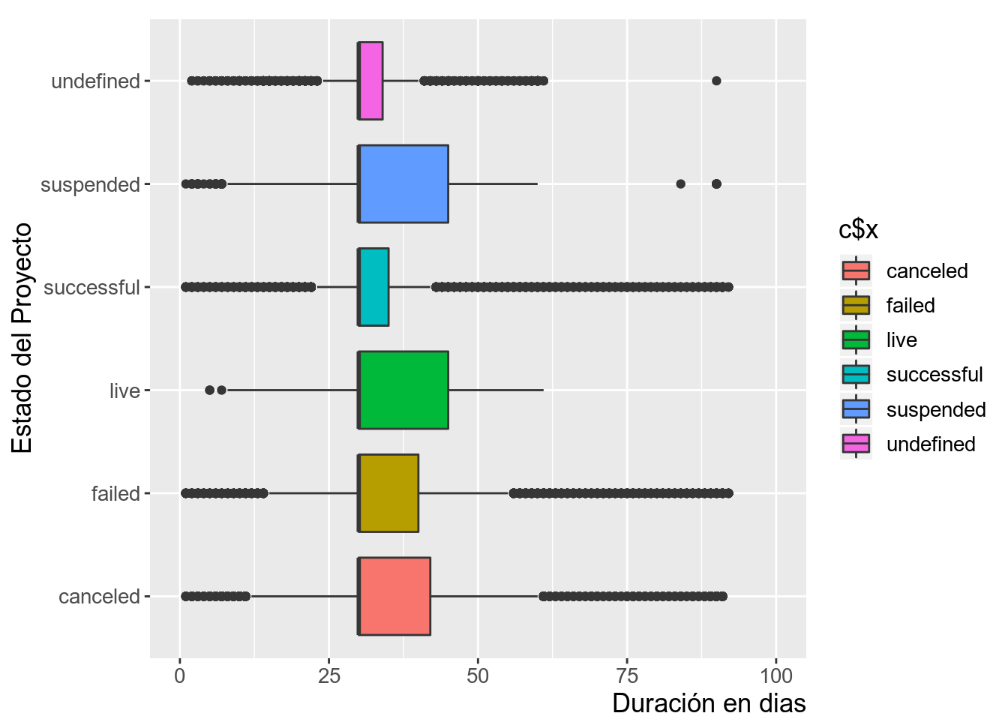
A partir del gráfico, se puede observar que la gran parte de proyectos éxitosos tienen una duración de a lo más un mes. Esto refuta la hipótesis de que más tiempo podría implicar una tendencia a alcanzar las metas de financiamiento. Sin embargo, los proyectos cancelados, suspendidos y fallados duran, en su mayoría, un mes. Por lo tanto, no se puede encontrar una relación contraria que indique que más tiempo para el proyecto genera una tendencia al fallo.
Conclusiones de la Exploración de Datos¶
Se partió analizando los proyectos exitosos y viendo que caracteristicas tenian en comun, que es lo más obvio que se repetía.
Tal como mostraron los gráficos, estas diferencias son principalmente:
La categoría general del proyecto
El país de origen del proyecto
La moneda utilizada
La duración en dias del deadline, aunque en menor medida y sin una relación clara
Se pudo notar que el USD es la moneda que acumula mas proyectos exitosos, esto se puede deber a que los proyectos que ocupan esta moneda son de EEUU que es además el lugar donde la mayoría del publico que ayuda en esta página pertenece. También se puede deber al carácter internacional de la moneda.
Esto se puede relacionar con que los clientes/usuarios se sientan mas beneficiados con proyectos locales al poder ver el beneficio directo en su vida, o con proyectos de un tipo mas internacional al poder esperar un beneficio "viral" en el mundo.
Así, este análisis elemental de los datos entrega algo de información sobre las hipótesis iniciales, pero es notorio que se necesitará realizar un análisis mas profundo con técnicas mas complejas de data mining para llegar a alguna conclusión mas fuerte (y difícil de observar al ojo humano).
Experimentos¶
Experimentos de Clasificadores¶
A partir de los comentarios obtenidos en las presentaciones terminamos nuestra aplicacion de clasificadores al dataset, los resultados se pueden apreciar a continuacion
Primero se filtra el dataset a solo columnas que se quieran usar para prediccion
### 2016
#Filter Canceled, Suspended, Undefined and Live projects
kickstarter_2016_filtrado = kickstarter_2016[(kickstarter_2016.state != 'canceled') & (kickstarter_2016.state !='live') & (kickstarter_2016.state !='suspended') & (kickstarter_2016.state !='undefined')]
kickstarter_2016_filtrado.state
#Group Canceled, Suspended and Failed in Failed
kickstarter_2016_noUndef_noLive = kickstarter_2016[(kickstarter_2016.state != 'undefined') & (kickstarter_2016.state !='live')]
kickstarter_2016_agrupado = kickstarter_2016_noUndef_noLive.replace({'state' : { 'canceled' : 'failed', 'suspended' : 'failed'}})
### 2018
#Filter Canceled, Suspended, Undefined and Live projects
kickstarter_2018_filtrado = kickstarter_2018[(kickstarter_2018.state != 'canceled') & (kickstarter_2018.state !='live') & (kickstarter_2018.state !='suspended') & (kickstarter_2018.state !='undefined')]
kickstarter_2018_filtrado.state
#Group Canceled, Suspended and Failed in Failed
kickstarter_2018_noUndef_noLive = kickstarter_2018[(kickstarter_2018.state != 'undefined') & (kickstarter_2018.state !='live')]
kickstarter_2018_agrupado = kickstarter_2018_noUndef_noLive.replace({'state' : { 'canceled' : 'failed', 'suspended' : 'failed'}})
Luego se define una funcion que ejecute clasificadores
# Simple function that trains a classifier and gets it's performance metrics
def run_classifier(clf, name, X, y, num_tests=100):
metrics = {'accuracy': [], 'precision': [], 'recall': [], 'f1-score': []}
for _ in tqdm(range(num_tests), desc="Running "+name):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.999, stratify=y)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
metrics['accuracy'].append(accuracy_score(y_test, y_pred))
metrics['precision'].append(precision_score(y_test, y_pred, average='macro'))
metrics['recall'].append(recall_score(y_test, y_pred, average='macro'))
metrics['f1-score'].append(f1_score(y_test, y_pred, average='macro'))
return metrics
print("Function 'run_classifier(clf, X, y, num_tests)' Defined")
Se crea una lista de clasificadores usables
# Classifiers available for multiclass classification
classifiers = {"2016": [], "2018": []}
for year in ["2016", "2018"]:
classifiers.get(year).append(("Dummy", DummyClassifier(strategy='stratified')))
classifiers.get(year).append(("Decision Tree", DecisionTreeClassifier()))
classifiers.get(year).append(("Gaussian Naive Bayes", GaussianNB()))
classifiers.get(year).append(("K Nearest Neighbours", KNeighborsClassifier(n_neighbors=5)))
print("Classifiers Initialized")
Se separan los datasets entre un conjunto de atributos usables para predecir y otro que consiste de lo que se desea predecir
# Classes and learning arguments are separated
X_2016 = kickstarter_2016_agrupado[['category', 'main_category', 'currency', 'deadline', 'goal', 'launched', 'pledged', 'backers', 'country']]
y_2016 = kickstarter_2016_agrupado[['state']]
X_2018 = kickstarter_2018_agrupado[['category', 'main_category', 'currency', 'deadline', 'goal', 'launched', 'pledged', 'backers', 'country']]
y_2018 = kickstarter_2018_agrupado[['state']]
print("Data Separated")
Ademas se convierten los tipos de las columnas del dataset para permitir ejecutar los clasificadores
# Unnecesary warnings are removed
pd.options.mode.chained_assignment = None # default='warn'
# All possible labels are collected
X_full_labels = pd.concat([X_2016, X_2018])
y_full_labels = pd.concat([y_2016, y_2018])
# Labels are turned into numerics
for column in ['category', 'main_category', 'currency', 'country']:
le = preprocessing.LabelEncoder()
le.fit(X_full_labels[column])
X_2016[column] = le.transform(X_2016[column])
X_2018[column] = le.transform(X_2018[column])
# Class labels are turned into numerics
for column in ['state']:
le = preprocessing.LabelEncoder()
le.fit(y_full_labels[column])
y_2016[column] = le.transform(y_2016[column])
y_2018[column] = le.transform(y_2018[column])
#Subsampling 2016 y 2018 sobre Failed
#idx = np.random.choice(y_2016.loc[y_2016.state == 0].index, size=100, replace=False)
#data_2016_subsampled = y_2016.drop(y_2016.iloc[idx].index)
# Dates are turned into numerics
for column in ['deadline', 'launched']:
X_2016[column] = pd.to_numeric(X_2016[column])
X_2018[column] = pd.to_numeric(X_2018[column])
from sklearn.exceptions import DataConversionWarning
from sklearn import warnings
warnings.filterwarnings(action='ignore', category=DataConversionWarning)
# Quantities are normalized
for column in ['deadline', 'goal', 'launched', 'pledged', 'backers']:
sc = preprocessing.MinMaxScaler()
sc.fit(X_full_labels[column].values.reshape(-1, 1))
X_2016[column] = sc.transform(X_2016[column].values.reshape(-1, 1))
X_2018[column] = sc.transform(X_2018[column].values.reshape(-1, 1))
# A certain bug within sklearn is taken care of
X_2016, y_2016 = check_X_y(X=X_2016, y=y_2016)
X_2018, y_2018 = check_X_y(X=X_2018, y=y_2018)
print("Data types re-configured")
Finalmente, los experimentos son ejecutados
# Main classification loop
for X, y, year in [(X_2016, y_2016, "2016"), (X_2018, y_2018, "2018")]:
for name, clf in classifiers.get(year):
metrics = run_classifier(clf, name, X, y)
print("----------------")
print("Resultados para: clasificador: ", name)
print(" anho: ", year)
print("Accuracy promedio: ", np.array(metrics['accuracy']).mean())
print("Precision promedio: ",np.array(metrics['precision']).mean())
print("Recall promedio: ",np.array(metrics['recall']).mean())
print("F1-score promedio: ",np.array(metrics['f1-score']).mean())
print("----------------\n\n")
A partir de lo anterior, se decide ejecutar desicion tree nuevamente, pues obtuvo los mejores resultados por lejos
Tambien se desea visualizar que tan bien predice
for X, y, year in [(X_2016, y_2016, "2016"), (X_2018, y_2018, "2018")]:
for name, clf in classifiers.get(year):
if name == "Decision Tree":
metrics = run_classifier(clf, name, X, y)
print("----------------")
print("Resultados para: clasificador: ", name)
print(" anho: ", year)
print("Accuracy promedio: ", np.array(metrics['accuracy']).mean())
print("Precision promedio: ",np.array(metrics['precision']).mean())
print("Recall promedio: ",np.array(metrics['recall']).mean())
print("F1-score promedio: ",np.array(metrics['f1-score']).mean())
print("----------------\n\n")
En la celda inferior se puede generar una visualizacion del clasificador, pero por temas de la enorme cantidad de memoria que ocupa se consideró que no es buena idea incluirla en el informe
# We try to visualize the Decision Tree
from sklearn.externals.six import StringIO
from IPython.display import Image
from sklearn.tree import export_graphviz
import pydotplus
dot_data = StringIO()
for name, clf in classifiers.get("2016"):
if name == "Decision Tree":
dtree = clf
break
export_graphviz(dtree, out_file=dot_data,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
# Uncomment the next line to generate visualization
#Image(graph.create_png())
Se reordenan los datos del dataset para permitir que los datos del 2016 se puedan usar con los del 2018
La idea es ver si desicion tree logrará predecir los resultados del 2018 a partir de los datos live del 2016
ksLive2016 = kickstarter_2016.loc[kickstarter_2016['state'] == 'live']
#kickstarter_2018_agrupado has sucessful and failed projects only
s1 = pd.merge(kickstarter_2018_filtrado, ksLive2016, how='inner', on=[ 'name', 'category', 'main_category', 'currency', 'goal', 'country'])
s1 = s1[['name', 'category', 'main_category', 'currency', 'deadline_y', 'goal', 'launched_y','pledged_y', 'state_x', 'backers_y','country']]
s1 = s1.rename(columns = {'deadline_y' :'deadline', 'launched_y':'launched', 'state_x':'state', 'backers_y':'backers', 'pledged_y':'pledged'})
s1_X = s1[['category', 'main_category', 'currency', 'deadline', 'goal', 'launched', 'pledged', 'backers', 'country']]
s1_y = s1[['state']]
s1X = s1_X
s1y = s1_y
X_full_labels = pd.concat([s1X])
y_full_labels = pd.concat([s1y])
# Labels are turned into numerics
for column in ['category', 'main_category', 'currency', 'country']:
le = preprocessing.LabelEncoder()
le.fit(X_full_labels[column])
s1X[column] = le.transform(s1X[column])
# Class labels are turned into numerics
for column in ['state']:
le = preprocessing.LabelEncoder()
le.fit(y_full_labels[column])
s1y[column] = le.transform(s1y[column])
# Dates are turned into numerics
for column in ['deadline', 'launched']:
s1X[column] = pd.to_numeric(s1X[column])
from sklearn.exceptions import DataConversionWarning
from sklearn import warnings
warnings.filterwarnings(action='ignore', category=DataConversionWarning)
# Quantities are normalized
for column in ['deadline', 'goal', 'launched', 'pledged', 'backers']:
sc = preprocessing.MinMaxScaler()
sc.fit(X_full_labels[column].values.reshape(-1, 1))
s1X[column] = sc.transform(s1X[column].values.reshape(-1, 1))
# A certain bug within sklearn is taken care of
s1X, s1y = check_X_y(X=s1X, y=s1y)
print("Data re-ordered")
Luego se ejecutan predicciones sobre el dataset 2018 en base a los datos del 2016
# Prediction are made
predictionTest = dtree.predict(s1X)
i= 0
for index, valueX in enumerate(predictionTest):
valueY = s1y[index]
if(valueX == valueY):
i += 1
#Predictions are verified
res = i/len(predictionTest)
print("--------------------------------------------------------")
print("Porcentaje de proyectos predichos correctamente: ",str.format("{0:.3f}", res*100))
print("--------------------------------------------------------\n\n")
Se considera que este porcentaje no es informacion suficiente, asi que se buscan metricas complementarias
# https://scikit-learn.org/stable/modules/model_evaluation.html
from sklearn.metrics import confusion_matrix
y_pred = predictionTest
y_true = s1y
def tn(y_true, y_pred): return confusion_matrix(y_true, y_pred)[0, 0]
def fp(y_true, y_pred): return confusion_matrix(y_true, y_pred)[0, 1]
def fn(y_true, y_pred): return confusion_matrix(y_true, y_pred)[1, 0]
def tp(y_true, y_pred): return confusion_matrix(y_true, y_pred)[1, 1]
accuracy = (tp(y_true, y_pred) + tn(y_true, y_pred))/(tn(y_true, y_pred)+fp(y_true, y_pred)+fn(y_true, y_pred)+tp(y_true, y_pred))
precision = tp(y_true, y_pred)/(tp(y_true, y_pred)+fp(y_true, y_pred))
recall = tp(y_true, y_pred)/(tp(y_true, y_pred)+fn(y_true, y_pred))
f1 = (2*(recall * precision))/(recall + precision)
print("----------------")
print("Resultados para: Test: ", 'Decision Tree')
print(" anho: ", '2016 -> 2018')
print("Accuracy: ", accuracy)
print("Precision: ", precision)
print("Recall: ", recall)
print("F1-score: ", f1)
print("----------------\n\n")
Conclusiones de Experimentos de Clustering¶
Dado que hicimos un clasificador y sacamos altas probabilidades de predicción,
por ejemplo en el Decision Tree; en donde el Accuracy es de 0.82 y un Precision de 0.66
esto se puede interpretar como que el programa es relativamente bueno prediciendo
exitos y no exitos en general, pero comete bastantes errores de tipo False Negatives ( de ahí
el 0.66), podemos intuir a partir de esto, dado que el valor 0.83 esta bastante por encima del
"Dummy",que es razonable entonces que existan atributos que caractericen a los proyectos exitosos, y por
ende es el paso siguiente lógico es el hacer un cluster para buscar cuales son estos atributos.
Con respecto a los clasificadores en si, podemos decir que Decision Tree es el mejor también para
el año 2018, teniendo un Accuracy de 0.81, pero notemos que esto puede cambiar con un par de
mejoras en el clasificador (que corresponde a subsampling, que es lo que se está trabajando)
Finalmente, se profundiza el experimento de clasificadores. Así, se busca verificar nuestro Decision Tree con el que se había obtenido una performance bastante buena (Accuracy y Precision elevados). Nuestro objetivo para este hito era predecir el resultado los proyectos en curso del año 2016. Esto se verifica comparando con el estado del proyecto en el año 2018. Los resultados de este experimento fueron sorprendentes: un 89% de los proyectos fueron clasificados correctamente. A partir de esto se puede afirmar que el clasificador funciona de muy buena manera. Esto hace pensar que es posible predecir el éxito de un proyecto en Kickstarter.
Cabe decir que se pretendía implementar un Random Forest pero debido al tiempo que de aprendizaje de un sólo Decision Tree esta opción fue descartada. Asimismo, en este Hito se ejecutaron de nuevo los clasificadores obteniendos perfomances inesperadamente altas. Estas son del orden de un 99% de correctitud. A pesar de buscar la razón de este cambio en lo resultados no se ha podido encontrar.
Experimentos de Búsqueda de Reglas de Asociacion¶
Para empezar el analisis se transforman las columnas launched y deadline a una columna duration que contiene la resta de ambos valores.
Luego esta duracion de tiempo es dividida en deciles.
Ademas las columnas con valores numericos son tambien clasificadas en deciles, para faclitar el analisis del algoritmo.
# The dataset is copied
kickstarter_2016_categorico = kickstarter_2016
kickstarter_2018_categorico = kickstarter_2018
# A duration column is added
kickstarter_2016_categorico['duration'] = (kickstarter_2016_categorico['deadline'] - kickstarter_2016_categorico['launched']) / pd.Timedelta(days=1)
kickstarter_2016_categorico = kickstarter_2016_categorico.drop('deadline', 1)
kickstarter_2016_categorico = kickstarter_2016_categorico.drop('launched', 1)
kickstarter_2018_categorico['duration'] = (kickstarter_2018_categorico['deadline'] - kickstarter_2018_categorico['launched']) / pd.Timedelta(days=1)
kickstarter_2018_categorico = kickstarter_2018_categorico.drop('deadline', 1)
kickstarter_2018_categorico = kickstarter_2018_categorico.drop('launched', 1)
# All non categorical columns are categorized
for column in ['duration', 'goal', 'pledged', 'backers', 'usd pledged', 'usd_pledged_real']:
if column != 'usd_pledged_real':
kickstarter_2016_categorico[column] = pd.qcut(x=kickstarter_2016[column], q=4, labels=False, duplicates='drop').astype('category')
col1 = []
for index, item in enumerate(kickstarter_2016_categorico[column]):
col1.append(column+str(item))
ser1 = pd.Series(col1, dtype="category")
kickstarter_2016_categorico = kickstarter_2016_categorico.drop(column, 1)
kickstarter_2016_categorico[column] = ser1
kickstarter_2018_categorico[column] = pd.qcut(x=kickstarter_2018[column], q=4, labels=False, duplicates='drop').astype('category')
col2 = []
for index, item in enumerate(kickstarter_2018_categorico[column]):
col2.append(column+str(item))
ser2 = pd.Series(col2, dtype="category")
kickstarter_2018_categorico = kickstarter_2018_categorico.drop(column, 1)
kickstarter_2018_categorico[column] = ser2
pass
kickstarter_2018_categorico = kickstarter_2018_categorico.drop('ID', 1)
kickstarter_2016_categorico = kickstarter_2016_categorico.drop('ID', 1)
kickstarter_2018_categorico = kickstarter_2018_categorico.drop('name', 1)
kickstarter_2016_categorico = kickstarter_2016_categorico.drop('name', 1)
kickstarter_2016_categorico = kickstarter_2016_categorico.drop('country', 1)
kickstarter_2016_categorico = kickstarter_2016_categorico.drop('currency', 1)
kickstarter_2016_categorico = kickstarter_2016_categorico.drop('duration', 1)
kickstarter_2016_categorico = kickstarter_2016_categorico.drop('category', 1)
kickstarter_2016_categorico = kickstarter_2016_categorico.drop('backers', 1)
kickstarter_2018_categorico.head()
kickstarter_2016_categorico.head()
Ahora con el dataset discretizado se puede ejecutar el algoritmo apriori, que encuentra reglas de asociacion
listed = kickstarter_2016_categorico.values.tolist()
frequent_itemsets = apriori(listed, min_support=0.1, min_confidence=0.1)
frequent_itemsets
Se recomienda al lector, que quiera ejecutar los experimentos, que juegue con los parametros del codigo anterior, para observar los distintos conjuntos posibles de reglas de asociacion
En la siguiente tabla se muestran un par de reglas de asociación que parecen interesantes (e intuitivas a la vez) Estas tienen un título explicativo dado que la idea de la validación de las reglas de asociación es encontrarle ua justifiación a "porqué" están relacionándose esos atributos de tal forma.
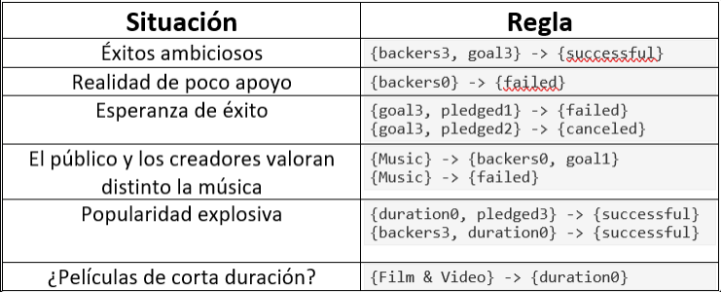
Analicemos un par de filas. La primera se denominó "Exitos Ambiciosos", dado que se puede ver una relacion entre proyectos que tienen metas altas (goal3 es el cuartil más alto de metas), y tenían mucho apoyo, tendiendo al exito. Esto se puede relacionar en la vida real a las ideas que llaman mucho la atención del público, y logran altos niveles de apoyo, a la vez, estas ideas son a veces muy ambiciosas; como se sabe el potencial de ellas, Y por ende tienen metas altas.
La segunda fila se denominó "Realidad de poco apoyo", esto simplemente nos dice, como los proyectos que no tienen mucho apoyo, evidentemente fallan.
La quinta fila se denominó "Popularidad explosiva", esta regla representa de buena manera lo viral que se pueden hacer algunos proyectos, dada la creatividad o buena idea. Estos tienen poca duración y logran mucho apoyo y dinero; siendo, por ende, exitosos.
Conclusiones Experimentos de Reglas de Asociación¶
Podemos notar que no se encuentran asociaciones particularmente interesantes y con esto se hace referencia a que las relaciones mostradas son elementos que tiene se pueden derivar solo de sentido común. En caso de que no existiera un modelo en la actualidad sobre lo que significa oferta y demanda, y sentido lógico con respecto al comportamiento de la gente; estas reglas serían innovadoras. Pero como todos sabemos que si te apoyan poco es lógico que no tengas éxito, y que poco apoyo significa poco dinero.
Los resultados de las reglas de asociaciónse puede deeber a la fuerte correlación entre backers y pledge, lo que tiene sentido dadoque el apoyo de la gente viene dado de manera monetaria. Al sacar una de estas dos variables,los resultados siguen siendo intuitivos y lógicos, modelando como los proyectos que fallan son básicamente los que no alcanzaron su meta (recordando que esa es la definición de éxito para kickstarter, y que si no se junta el dinero, no se alcanza la meta)
Un par de cosas que si podemos desprender son, como se ve modelado el hecho de que la gente valore un poco menos cosas como la música versus los artistas esto se ve en como, los creadores de proyectos músicales tienden a pedir más de lo que la gente está dispuesta a pagar, y por ende tienen peores resultados.
Con respecto a la relación con los clasificadores, podemos notar que las reglas de asociación son una excelente manera de darse cuenta que el clasificador probablemente está sufriendo un caso de overfitting (falta hacer crossvalidation) dado que en caso de ser efectivamente cierto que el clasificador es capáz de predecir correctamente más del 98% del resultado de los proyectos solo en base a un par de atributos, nos da a entender que hay una reseta más o menos clara de cosas que tienden a pasar en los proyectos exitosos a diferencia de los fallidos. Pero esto no se está encontrando ninguna relación clara en las reglas de asociación como para que esto tenga mucho sentido.
Conclusiones de Proyecto¶
Recapitulando entonces, notamos que se trató de ver relaciones entre el éxito de un proyecto en kickstarter y caracteristicas de esto.
Para esta investigación se llevaron a cabo diferentes procesos. En primer lugar, se llevó a cabo un analisis de datos y un preprocesamiento.
Los datos se trabajaron en R y en Python ,en donde se tuvo que acomodar la manera en la que estaban guardados los datos (puntos y comas etc) para que estos se pudieran leer de buena forma), luego de otras limpiezas, se pudo explorar los datos y ver indices como "tipos de proyecto que ocurren con más frecuencia" y cuales tienen más porcentaje de éxitos.
Luego de esta limpieza de datos, se implementó la herramienta de clasificadores, en donde se obtuvieron resultados considerables solo en el "decision tree" en donde los resultados fueron tan altos, que se tuvo que tratar de extrapolar los datos para verificar que tan bueno era el clasificador tomando proyectos del 2016 que estaban inconclusos en ese año y que estaban presentes el 2018, para ver si se predecía correctamente el resultado de estos con el clasificador generado para el 2016 (Obteniendo un F1-score de 0.76).
Por último, se volvió a procesar los datos para poder trabajarlos como clasificadores, conviertiendo los atributos númericos en intervalos de números de forma categórica (utilizando cuartiles). A partir de esto, se generaron reglas de asociación, en donde los resultados obtenidos modelaban muy bien el comportamiento de los atributos de la aplicación, pero no eran capaces de sacar reglas particularmente intersantes o fuera de lo intuitivo.
Recordando las hipotesis, se tiene:
Los proyectos que se financian por más tiempo tienden a tener éxito:
- No se encontraron fundamentos para apoyar esta hipotesis, se pudo apreciar que los indices de éxito y fracaso ocurrian de la misma manera independiente de la duración de estos.
Los proyectos tecnológicos son los más financiados:
- Tampoco se encontraron fundamentos para apoyar esta hipotesis. Aunque tendemos a reconocer como ideas famosas los proyectos tecnológicos, esto se debe al gran número de proyectos tecnológicos que hay, pero cuando se ven los porcentajes de éxito se puede notar que es un ambiente muy competitivo.
Mientras más fondos se necesiten, más se financia:
- Para esta hipotesis podemos sacar un "depende". Esta hipotesis es muy subjetiva, y depende del valor de la idea (que no se puede modelar como atributo). Pero podemos notar que si una idea es buena, entonces aunque se pidan más fondos, estos se van a cumplir de igual forma.
Los proyectos que están en dólares tienden a tener más éxito:
- Esto es falso, nuevamente se puede notar que la frecuencia de proyectos en dólares es mucho mayor a las otras unidades monetarias, es por eso que la percepción de que los proyectos éxitosos tienden a estar en dólares. Pero no tiene que ver con la mercancía en si.
Los proyectos simples son los que más tienden a tener éxito:
Este es un resultado inferible como cierto a través del analisis exploratorio, esto quiere decir que son ideas fáciles de ejecutar y en particular piden poco dinero.
Se pudo ver este tipo de proyectos tendían a ser más financiados. (Tiene que ver quizas con el dicho: "las ideas más simples son las mejores")
Kickstarter es una plataforma recomendada para todo crowdfunding:
- No se puede sacar una conclusión para esta hipotesis dado el proyecto que se hizo, se necesitaría investigar proyectos a través de otras plataformas para comparar los resultados.
A partir de esta última hipotesis, podemos plantear siguientes investiaciones que se podrían hacer para continuar con el proyecto. Partiendo por analizar más datos de otras fechas, de otras plataformas, repetir experimentos; y a partir de todo eso se podría crear una guía para proyectos que represente factores que sean influenciables para el éxito.
Inclusive, a partir de esto se podrian generar consultorías para ayudar a proyectos con ideas buenas pero mala administración de lo que se necesita.
Con esto, volvemos a plantar entonces ¿Un éxito en Kickstarter, realmente significa que el proyecto fue exitoso?. Todo este analisis muestra herramientas utiles capaces de predecir el resultado de distintos eventos. Pero siempre al terminar de analizar hay que volver al origen y plantearse. "Este éxito en la aplicación, ¿es representativo de un éxito en la realidad?"